

Voici quelques années encore, tout le monde ne parlait que de big data, mais désormais chacun sait finalement ce qu’il faut faire avec toutes ces données : entraîner des modèles. Alors que le machine learning et le deep learning étaient voici peu encore le terrain de chasse réservé d’entreprises comme IBM et Google, voire de quelques start-up en vogue, la technologie est désormais accessible à d’autres organisations. Mais qu’entend-on en fait par apprentissage profond ?
Si vous recouriez voici quelques années à Google pour traduire un texte, le constat était sans appel : traduction farfelue, syntaxe étrange. Bref, c’était clairement mauvais. Mais aujourd’hui, la différence par rapport à un traducteur humain n’est plus aussi grande. Le service s’est très nettement amélioré sur une durée manifestement assez courte. L’explication ? Le machine learning.
” En fait, l’IA n’a rien de nouveau, précise Mieke De Ketelaere, directrice Customer Intelligence West-Europa chez SAS, dans le cadre d’une soirée Straffe Madammen sur l’intelligence artificielle. Mais autrefois, l’intelligence informatique était surtout codée sous forme si-alors. Il s’agissait en fait d’une intelligente toute relative. ” Ainsi, alors que Google Translate devait se contenter autrefois de règles linguistiques traduites sous forme de code, tel n’est plus le cas depuis longtems. ” L’IA est nettement plus performante si elle est basée sur l’expérience, précise De Ketelaere. On apprend une langue par le dialogue, tandis que l’expérience permet de rendre un système plus intelligent. ”
La reconnaissance faciale ne porte donc pas sur des yeux bleus ou des cheveux bruns : pour un ordinateur, un visage est une succession de 128 nombres.
L’idée sous-jacente est que l’ordinateur complète lui-même la logique, sans que tout soit écrit au préalable. ” Reconnaître un chien d’un chat, un enfant de 3 ans en est capable, poursuit De Ketelaere. Mais pour un ordinateur, c’est difficile car il est impossible de définir des règles. Les animaux ont tous 4 pattes, une queue, etc. Nous l’avons enfin appris aux ordinateurs en taggant de très nombreuses photos et en les présentant ensuite à la machine. ”
Machine learning contre deep learning
Entraîner un ordinateur en lui présentant toute une série de données labelisées, tel est au final le machine learning. C’est également la manière d’obtenir de l’IA ‘puissante’. ” Songez aux courriels que vous taggez, explique De Ketelaere. En indiquant spam et non-spam. Ou pour des images : ceci est un château et ceci pas. Après un certain temps, l’ordinateur en arrive à pouvoir indiquer lui-même, lorsqu’il voit une image, qu’il s’agit ou non d’un château. Mais pour ce faire, il faut disposer de beaucoup de données historiques. ” Certaines des applications de reconnaissance d’images les plus sophistiquées sont d’ailleurs le résultat de crowdsourcing où les utilisateurs sont impliqués dans ce travail de labélisation très chronophage. ” Un exemple en est la reconnaissance faciale de Facebook, note De Ketelaere. Chaque fois qu’une photo est taggée, vous aidez à entraîner le système. ”
Le deep learning est l’étape suivante, un sous-ensemble de l’apprentissage machine qui s’appuie sur plusieurs couches. Souvent, il s’agit de couches qui scindent les données en informations facilement traitables. De Ketelaere cite un exemple trivial. ” Pour la reconnaissance faciale, on va tirer des vecteurs entre les zones sombres et claires, ce qui permettra de tenir également compte de différents angles de l’appareil photo. Le système établira ensuite des repères afin de pouvoir présenter l’image de face. Enfin, il essaiera de reconnaître la personne. Il s’agit donc de 3 étapes pour obtenir finalement un code de 128 variables, unique pour chaque individu. La reconnaissance faciale ne porte donc pas sur des yeux bleus ou des cheveux bruns : pour un ordinateur, un visage est une succession de 128 nombres. ”
A cet égard, le deep learning est l’une des techniques possibles parmi d’autres, insiste Danny De Schreye, coordinateur du programme de mastère en intelligence artificielle à la KU Leuven. ” L’apprentissage machine compte de nombreuses familles et des approches différentes. Globalement, on peut les scinder en approche sub-symbolique et approche symbolique. Parmi les sub-symboliques, on retrouve les réseaux neuronaux artificiels. Un tel système est une imitation grossière du fonctionnement du cerveau. A l’opposé, on retrouve de très nombreuses autres manières : classifications, arbres décisionnels, apprentissage par renforcement, etc. ”
Votre jeu de données doit être complet, de qualité et, n’oublions pas, vous devez en être le propriétaire légal.
Réseaux neuronaux
La technique fort en vogue pour l’instant en le deep learning via les réseaux neuronaux. Comme son nom l’indique, un tel réseau neuronal imite le cerveau humain, précise De Kelelaere. ” Ce réseau se compose de neurones et de connexions entre ceux-ci. Lorsque l’on apprend, des connexions se font entre des neurones, tandis que le cerveau anticipe lorsqu’une situation similaire se produit ensuite. ” Tel est aussi le mode de fonctionnement du réseau neuronal artificiel : le système crée lui-même des couches et apprend aussi par lui-même.
” Le deep learning est un modèle mathématique. Des données entrent et des données sortent, avec entre les deux de nombreux petits boutons que l’on peut ‘régler’. Pour former le système, il faut disposer de ces données, ce modèle mathématique, et d’une règle d’apprentissage qui précise ‘voici ce qui sort et voici ce que je veux voir sortir.’ Et lorsqu’une erreur se produit, cette erreur est utilisée pour régler les boutons et ajuster donc le système “, explique Joni Dambre, professeur à l’UGent et membre de l’IDLab, l’un des groupes de recherches de l’Imec.
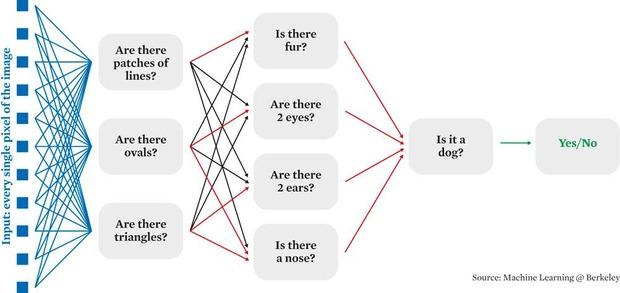
Et alors que dans les anciens systèmes de machine learning, c’étaient encore des personnes qui réglaient ces boutons, il en va autrement dans les réseaux neuronaux. ” Les anciens systèmes étaient limités par l’intelligence de l’homme qui devait imaginer les différents cas. Mais désormais, le réseau neuronal va les rechercher lui-même en créant différentes couches. Lorsque des données entrent, par exemples les pixels d’une image, ceux-ci sont envoyés à différents neurones qui exécutent un calcul rapide avant de les renvoyer à la couche suivante. Ensuite, toutes ces données sont à nouveau mélangées et ainsi de suite, couche après couche, dixit Dambre. Finalement, l’algorithme d’apprentissage va lui-même toucher à tous ces boutons, et il peut y en avoir des millions, pour affiner le modèle. Après quoi des techniques de visualisation peuvent être appliquées pour découvrir par exemple que tel neurone apprend à reconnaître ce qui ressemble à une fleur, et qu’un autre pourra identifier la fourrure d’un animal. ”
Boîte noire
Un réseau neuronal n’est donc pas toujours une boîte noire que l’on alimente en données qui ressortent ensuite sans que l’on sache très bien pourquoi le système obtient de telles données. En fait, ce mystère tient plutôt au type de modèle, estime De Schreye. ” Les gens qui l’utilisent pour le langage naturel me disent qu’elles n’ont aucune idée de ce qui se passe au niveau des couches. Ce qui en sort ne ressemble en rien à ce qu’elles reconnaissent avec leurs théories linguistiques. ”
Dans le cas de la reconnaissance d’images, la situation est un peu plus simple, considère Dambre. ” Il existe des manières de visualiser sur lesquelles réagit un tel neurone. C’est ainsi qu’il est possible de voir dans la 2e couche d’un tel système de reconnaissance d’images qu’un neurone réagit par exemple à des formes rondes, alors que dans d’autres couches, d’autres neurones réagiront à des formes de nid d’abeille. Si l’on regarde encore plus avant, on peut s’apercevoir par exemple qu’on obtiendra des yeux ou des visages. Les éléments auxquels réagit un neurone deviennent toujours plus complexes au fil des couches. On part donc de choses simples comme des lignes ou des angles pour obtenir des visages, des mains, etc. Et au final, on obtient par exemple un détecteur de chien comme l’un de ces neurones, ou un détecteur de voiture ou de personnes. ”

Sous le capot
De tels systèmes complexes exigent de la puissance de calcul. Pas étonnant dès lors que ces réseaux neuronaux connaissent maintenant un tel engouement, estime De Schreye. ” La taille de ces réseaux à véritablement explosé tandis que la quantité d’exemples introduits a pris des proportions énormes. Grâce à l’augmentation des puissances de calcul en effet, il est possible d’alimenter les systèmes avec des volumes gigantesques. Du coup, il est possible de résoudre des tâches autrefois impossibles à réaliser, simplement parce que la puissance n’était autrefois pas disponible. ”
A cela s’ajoute que la technologie est dé-sormais relativement mature, note Joni Dambre. ” C’est ainsi que le deep learning devient assez stable. Du coup, davantage d’outils voient le jour. On trouve notamment des plates-formes comme Keras permettant de construire plus facilement un système d’apprentissage profond. Une fois que l’on sait l’architecture que l’on veut, il suffit de quelques lignes de code. Les éléments les plus complexes sont cachés sous le capot. ”
Alors qu’une entreprise avait autrefois besoin d’un consultant comme SAS pour l’apprentissage machine, et certainement pour l’apprentissage profond, un informaticien peut à présent se lancer dans un projet clairement défini. Même si les experts mettent en garde contre les dangers d’une telle approche.
Crap in, crap out
Celui qui suit un peu l’actualité se souvient d’exemples de systèmes d’IA qui faisaient état de préjugés ou de propos racistes ou sexistes. Dans la plupart des cas, le coupable doit être recherché dans les jeux de données qui forment ces systèmes d’IA. ” Beaucoup dépend des données de base de la formation, explique De Ketelaere. C’est ainsi qu’au début, Alexa ne reconnaissait par exemple pas les voix d’enfant. Parfois, un système ne distinguera pas des personnes de minorité dans la reconnaissance d’images. En cause, le fait que la base de données ne soit pas complète. C’est le ‘crap in, crap out’. Votre jeu de données doit être complet, de qualité et, n’oublions pas, vous devez en être le propriétaire légal “, insiste-t-elle, avec un clin d’oeil à Cambridge Analytica.
Il est de la responsabilité de celui qui entraîne le système de veiller à ce que les données soient représentatives. Qu’il n’y ait pas de biais.
L’exemple le plus connu de ce principe de ‘crap in, crap out’ est sans doute Tay, le chatbot proposé par Microsoft sur Twitter et qui est rapidement devenu fan d’Hitler. ” Si vous entraînez un chabot sur base de messages qui renferment de nombreux propos racistes, il va les imiter, explique Dambre. C’est en effet ce qu’il a appris à faire. ‘Vous me dites : si je vois ceci, voilà ce qui doit en sortir, je vais l’imiter autant que possible’. ” Tay est surtout l’exemple de ce qu’il ne faut pas faire. ” En général, le deep learning est utilisé comme une forme d’apprentissage supervisé, poursuit Dambre. Dans les données de formation, chaque exemple doit avoir un label, tandis que les données doivent être représentatives. Si vous voulez que l’IA apprenne à reconnaître un renard, il faut lui présenter des renards et donc des images qui représentent des renards. Il est de la responsabilité de celui qui entraîne le système de veiller à ce que les données soient représentatives. Qu’il n’y ait pas de biais. ”
Un autre exemple d’échec est celui du Dr Sameer Singh de l’Université de Californie qui avait utilisé un réseau neuronal pour apprendre à distinguer les loups des huskys. Le réseau a donné des résultats étonnamment bons jusqu’à ce que l’on constate qu’il avait trouvé une faille. L’analyse a en effet montré que le réseau ne s’entraînait pas au départ des visages des animaux ou de la forme spécifique de la queue, mais bien de l’arrière-plan de l’image. En effet, les huskys étaient en général dans un paysage de neige. Pour le réseau donc, neige était synonyme de husky. ” En soi, un tel système est relativement stupide, estime Dambre. Il cherche la manière la plus simple d’établir un lien. Lorsque l’on entraîne donc un tel système, il faut veiller à présenter suffisamment de contre-exemples. ”
Dès lors, la phase de test est pratiquement aussi importante que la phase d’apprentissage. Pour l’apprentissage machine, chaque jeu de données doit être scindé en 2, estime De Ketelaere. Un jeu pour former et l’autre pour tester. Ce faisant, on peut vérifier si le système est dans le bon et savoir si, lorsque l’on donne de nouvelles données dont on ne sait pas ce qu’elles sont, le système les reconnaît correctement. Il faut avoir confiance dans la capacité du système à réussir. ”

Comment mystifier l’IA ?
L’université de Berkeley vient de mener une étude surprenante. Dans ce cadre, des étudiants ont étudié la manière de glisser des ‘ordres’ cachés dans des morceaux de musique qu’un assistant numérique comme Alexa devrait respecter en écoutant de telles musiques. Auparavant, des étudiants chinois avaient déjà trouvé une méthode pour traiter des ordres dans un bruit de fond. Il s’agit là d’exemples que le labo n’a pas encore fait aboutir, mais qui montrent qu’une personne inventive peut très bien mystifier l’IA. ” L’apprentissage profond est un modèle excessivement puissant, précise Dambre. Il est capable d’imiter pratiquement n’importe quel rapport entre data in et data out. Mais pour bien fonctionner, il faut le rendre redondant afin de lui offrir de nombreuses manières d’établir ces liens. C’est la raison pour laquelle il est parfois facile de le tromper. ” Autre exemple : la ‘falsification’ de photos. Ainsi, la même photo d’un panda peut, moyennant l’ajout de quelques pixels dans le système, être ‘reconnue’ comme un gibbon. ” Avec les mêmes techniques d’entraînement que celles utilisées pour régler le modèle, il suffit de modifier très légèrement les données d’entrée pour obtenir un résultat différent. Alors que nous ne voyons pas la différence entre les 2 images. ” C’est d’ailleurs une matière qui fait l’objet d’études. ” De très nombreuses recherches sont menées sur cet effet contradictoire, mais pour l’instant, la plupart des chercheurs sont pour l’instant d’avis qu’il est impossible de l’éviter si l’on utilise de tels réseaux puissants. Il est possible de le minimiser, mais pas de le supprimer. “